Un equipo de investigadores de Google Research desarrolló un modelo de detección en tiempo real basado en la estimación de las poses que puede identificar a las personas mientras se comunican con señas
Google trabaja en tecnologías para hacer más accesibles las videollamadas y con este objetivo desarrolló un nuevo sistema que permite detectar en tiempo real cuándo un participante utiliza la lengua de signos, con el objetivo de destacarlos en las videollamadas grupales.
La mayor parte de los servicios de videollamadas utilizan sistemas para destacar a las personas que hablan en voz alta en las reuniones grupales, algo que supone inconvenientes para las personas con problemas de audición cuando se comunican mediante lengua de signos.
Para solucionar este problema, un equipo de investigadores de Google Research ha desarrollado un modelo de detección de la lengua de signos en tiempo real basado en la estimación de las poses que puede identificar a las personas como hablantes mientras se comunican con esta lengua.
El sistema desarrollado por Google, presentado en la conferencias europea de visión computarizada ECCV’20, emplea un diseño ligero con el que reduce la cantidad de carga de CPU necesaria para ejecutarlo, para no afectar así a la calidad de las llamadas.
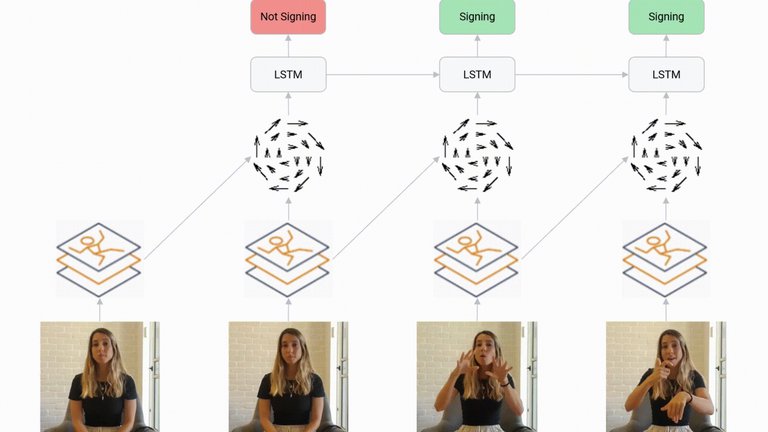
La herramienta utiliza un modelo de estimación de poses de brazos y manos, conocido como PoseNet, que reduce los datos de la imagen a una serie de marcadores en los ojos, nariz, manos y hombros del usuarios, entre otros, de manera que se detecta también el movimiento.
El modelo de Google presenta cerca del 80 por ciento de efectividad detectando a las personas que hablan lengua de signos cuando emplea tan solo 0,000003 segundos de datos, mientras que si se usan los 50 fotogramas anteriores la efectividad asciende hasta el 83,4 por ciento.
Lenguaje de señas Google
Asimismo, los investigadores añadieron una capa adicional al modelo, de arquitectura de memoria a largo y corto plazo, que incluye “memoria sobre los pasos de tiempo anteriores, pero sin retroceso”, y con la que logra una efectividad del 91,5 por ciento en apenas 3,5 milisegundos.
Para mejorar la accesibilidad de las plataformas de videoconferencias, los investigadores han hecho su herramienta compatible con ellas, para que pueda usarse para señalar como ‘hablantes’ a quienes utilicen lengua de signos.
Este sistema emite ondas de sonido ultrasónicas cuando advierte a una persona que emplea esta lengua, de forma que las personas no las pueden percibir pero sí sus tecnologías de detección del habla, que destacan así al usuario en las videollamadas.
“Para comprender mejor qué tan bien funciona la demostración en la práctica, realizamos un estudio de experiencia del usuario en el que se pidió a los participantes que usaran nuestra demostración experimental durante una videoconferencia y que se comunicaran a través del lenguaje de señas como de costumbre. También se les pidió que se firmaran entre sí y sobre los participantes que hablaban para probar el comportamiento de cambio de altavoz.
Los participantes respondieron de forma positiva cuando que el lenguaje de señas estaba siendo detectado y tratado como un habla audible, y que la demostración identificó exitosamente al asistente que firmaba y activó el ícono del medidor de audio del sistema de conferencias para llamar la atención sobre el asistente que firmaba”, se menciona en el comunicado difundido.
Los investigadores han publicado en código abierto en la plataforma GitHub su modelo de detección y esperan que su tecnología pueda “aprovecharse para permitir que los hablantes de lengua de signos utilicen las videoconferencias de manera más conveniente”.
(Con información de Portaltic)